Recursive crawling#
SOSSE can crawl recursively all pages it finds, or the recursion level can be limited when crawling large websites or public sites.
No limit recursion#
Recursing with no limit is achieved by using a policy with Crawl condition to Crawl all pages.
For example, a full domain can extracted with 2 policies:
A policy for the domain with a
URL regexthat matches the domain, andConditionset toCrawl all pagesA default policy (with the
URL regexset to.*) with aConditionset toNever crawl
Limited recursion#
Crawling pages up to a certain level can be simply achieved by setting a Crawl condition to Depending on depth and setting the Crawl depth when queueing the initial URL.

Partial limited recursion#
A mixed approach is also possible, by setting a Crawl condition to Depending on depth in one policy, and setting it to Crawl all pages in an other and a positive Crawl depth.
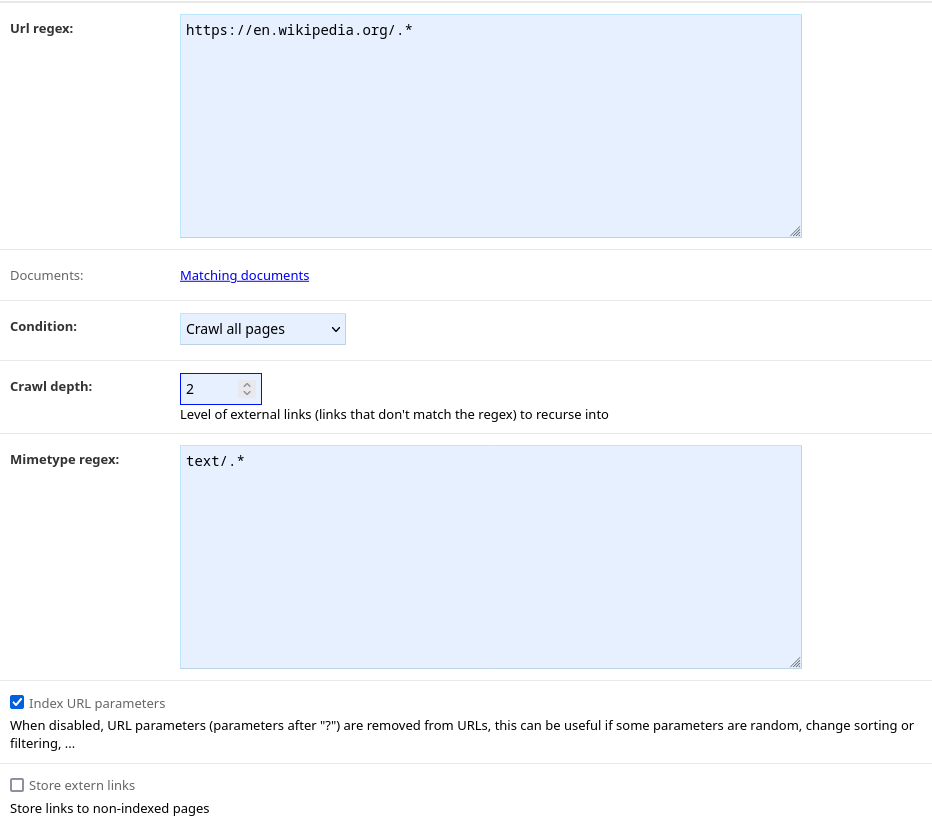
For example, one could crawl all Wikipedia, and crawl external links up to 2 levels with the following policies:
A policy for Wikipedia, with
Crawl depthof 2:
A default policy with a
Depending on depthcondition:
